
LLM Fine-tuning (Prompt Engineering)

Purpose
If I were to sit down at a prompt window with a Generative AI Art tool like MidJourney and ask for a Pirate it might render something like below. That’s what it does.

While that is a classic pirate look for sure, it’s not exactly what I wanted. So I would need to refine my prompt and instead of just asking for a “pirate” I might prompt it for a “rough pencil sketch of 1960’s comic book style pirate.”

“rough pencil sketch of 1960’s comic book style pirate”
As magical as that may be, if I were to ask it to generate a “Mozart inspired pirate concerto” it will let my music loving ears down. Because that isn’t what it’s purpose is. It’s purpose is to generate art, not music.
Persona
In my previous post, I asked you to watch a video about the various personas that might interact with Qlik’s Application Automation solution. So that you would understand why I was trying to generate very bespoke JSON workflows that met a users prompt. Actually, the goal would really be a copilot type chat, but on my budget and time constraints, I settled for copy and paste.
Initially the output was perfect. The more complicated the solution I was asking for, the more I struggled to get exactly what was needed. 1,217 right out of 1,220 characters wasn’t enough.
I didn’t realize the most important persona in the picture was “The model I was fine tuning” not the end user. I tweaked, and tuned and refined my training data set for both my previous posts, and I tweaked and tuned the way I asked for my desired workflow. But I never tweaked, or tuned, or refined the purpose I was giving the model I was trying to tune. I wasn’t giving it a specific purpose. I wasn’t providing it with a concise persona.
Prompt Engineering
As I look back at my initial LLM Fine-tuning post, I realize now that I actually got very lucky in that I was trying such a simple task. I had focused my energies on my training data set. I had focused my energies on naming my model. What I hadn’t even paid any attention to, was the prompt template that was being used to provide the purpose, the persona, the reason for the model to consume energy. I simply copied the default prompt that Predibase had provided me in a training exercise.
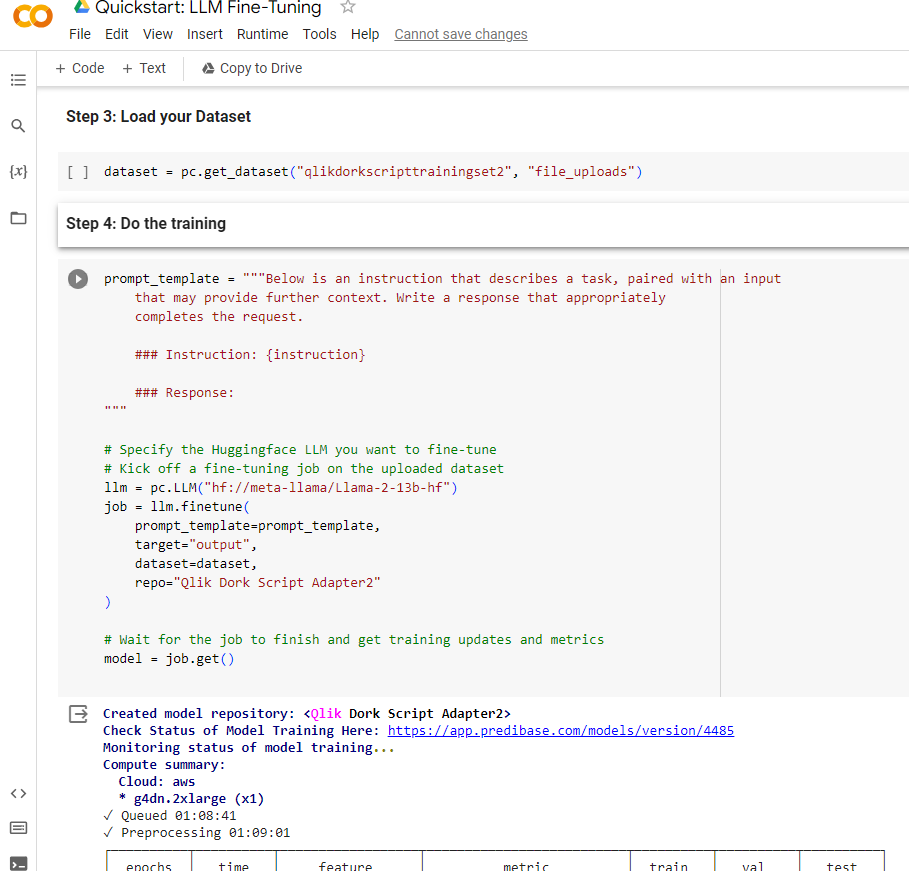
The Llam2 base model already knew how to generate code. While I needed to provide a training data set so it understood my Qlik Dork Script language it was still within the generic purpose of that model. While it worked for my simple workflow requests. It didn’t work for the more complex cases I continued asking for after publishing my workflow piece.
While you can tweak, refine, and tune the prompts you provide to MidJourney they have to fit within it’s purpose.
When you provide the proper “prompt template” to a model for fine-tuning, to provide it’s persona, it’s purpose, it’s reason for using electricity, that’s called prompt engineering. Predibase actually provides lots of examples, that in my haste I completely ignored.
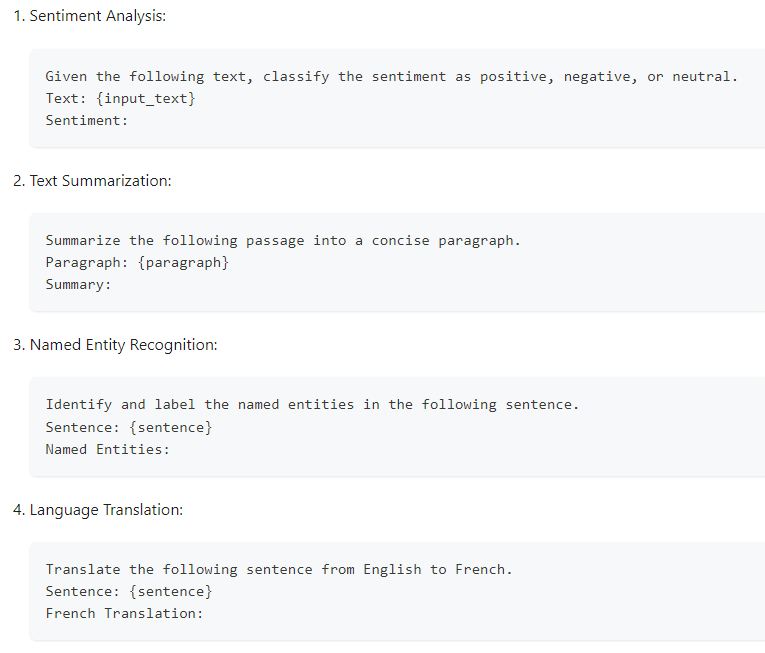
Those examples gave me something to work with, so I gave it a shot and tried my hand at prompt engineering:

My buddy Connor McCormick also provided a very robust prompt template that actually includes some examples to really guide the tuning:
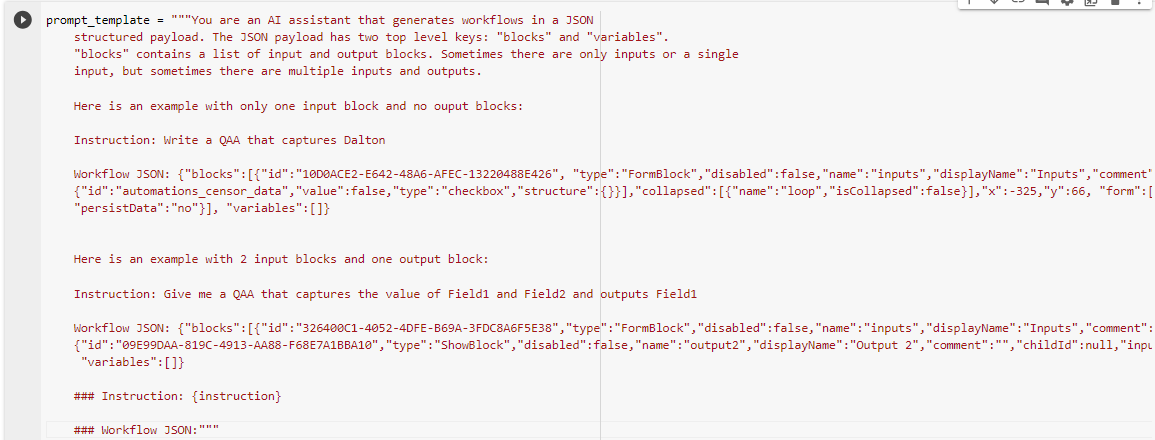
Lessons Learned
I was happy to be able to generate very simple single lines of code that were unique in the world. Even more ecstatic to get very, very close to generating the very bespoke JSON workflow syntax. Yet humbled by the fact that in my rush to do those things, I hadn’t taken the time to realize the importance of the prompt template. Surely, by this stage in my career I should have realized that training a model for a specific task deserved a template that identified the reason for it to exist and consume power. But I hadn’t. This process continues to intrigue and excite me and this week I learned:
- Users prompts can be tweaked, refined and tuned, but they must fit within the persona of the model.
- In addition to providing training data, fine-tuning involves prompt engineering, which means providing it a focused prompt template during the training process.
- Fine-tuning requires patience, patience and patience. Some of my prompt templates helped me produce better output, others didn’t. While I can tweak my “pirate” images within 1 minute, it was taking me between 17-24 hours to try and hone my prompt templates. My project was only for my own learning purposes. If your purpose is great enough, that time will be easily justified. Because it will mean you are taking one more bite out of that Generative AI elephant in the room.
- Fine-tuning requires a combination of starting with the right base model, the right training data set and the right prompt template. Take in the entire picture, don’t just focus on 1 element of it.
- While it didn’t generate actual music, the “Mozart inspirate Pirate concerto” prompt did produce the stunning featured image for this post. Which is simply a reminder, that every now and then we may get lucky even when we are doing the wrong thing. Which is a good thing because this Generative AI stuff is new for all of us. So keep trying. Keep failing. Keep learning. Keep adjusting.