Total Immersion How cool is this image of a physician totally immersed in patient data in this virtual world? As soon as the coolness wheres off your brain is left scrambling for reality. Can we really do this? Would it… Read more ›
Among the millions of great nuggets I’ve picked up from Robert Pearl in his awesome work “Mistreated: Why we think we’re getting good health care and why we’re usually not” one was especially memorable and challenging. He shared a story about… Read more ›
Great People One of the lessons in life that I’ve found to be very true was that you should surround yourself with great people. Gotta say I’m so amazingly blessed to have been able to learn from some of the… Read more ›
The real question that’s plagued the world has never been “Should I visualize the data?” it’s always been “How should I visualize the data?” Because it’s not that people don’t want to see things visually it’s a matter of how… Read more ›
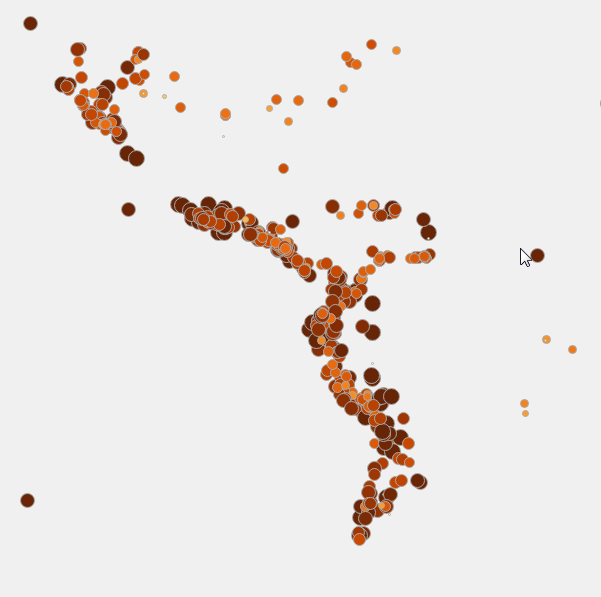
In my previous post I asked you to consider Population Health from a Global Perspective. I understand completely how hard that is to do. The world can be a scarier enough place without having to imagine how we can improve… Read more ›
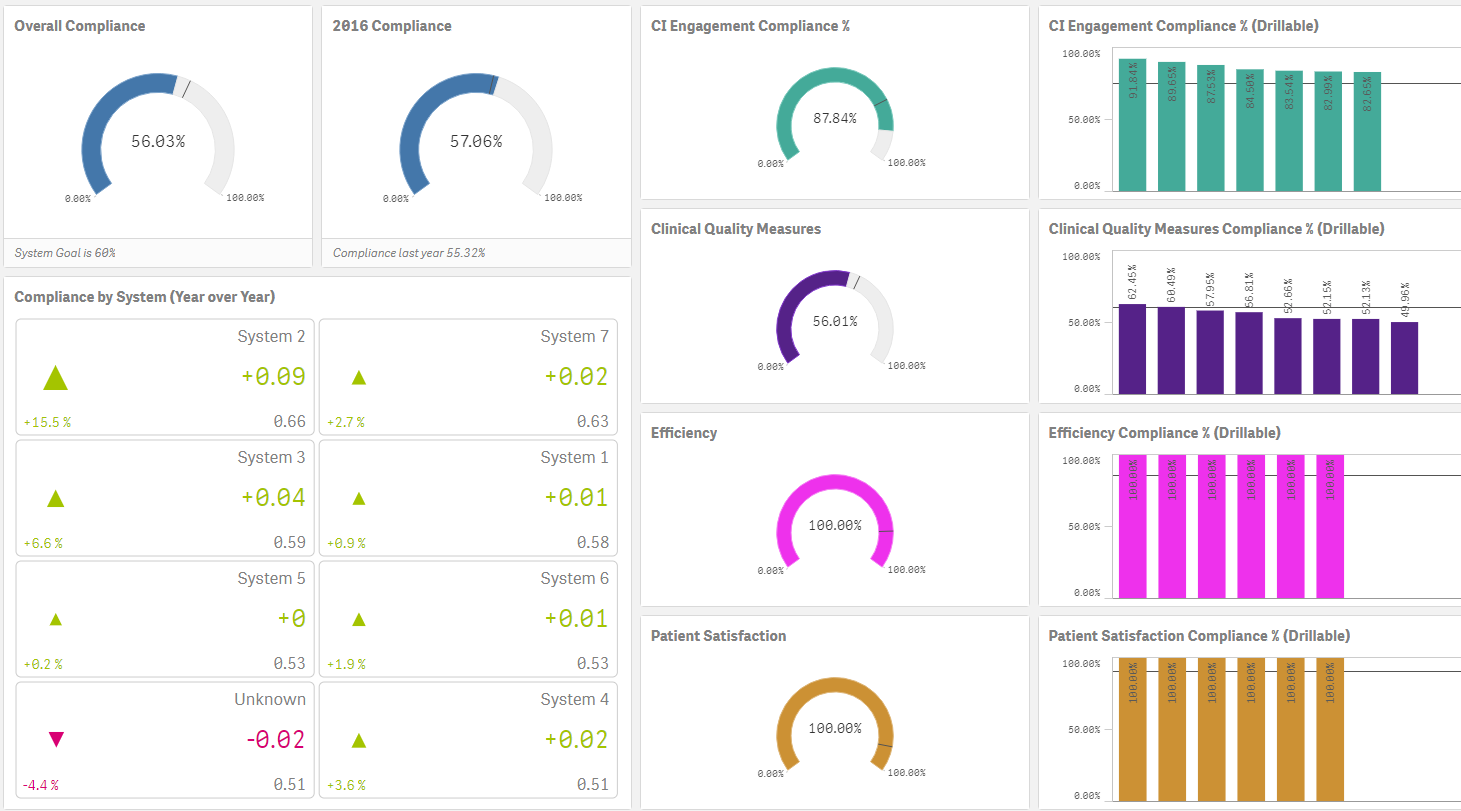
The Problem(s) with Population Health I’ve got a nickel that says you are probably undertaking a Population Health Initiative. Everyone else in the world is so it’s safe to say you are as well. As the Qlik Healthcare team travels… Read more ›
Wintality Several years ago I read the term Wintality via posts from Auburn softball players. I liked the term so much that I proceeded to write not 1, not 2 but 8 posts to my own softball related website. Each… Read more ›
My boy Sir Isaac Newton is famous for a few laws he wrote about motion. His first such law on the topic says: An object at rest will remain at rest unless acted on by an unbalanced force. An object… Read more ›
Oh sure those nerdy science types will give you explanations and “supposed” evidence that the world isn’t round. Blah-blah-blah. But let’s face it … we are humans and the way our brains work it’s simply easier to see things in… Read more ›
Ask any Data Visualization expert and one of the best pieces of advice that they will give you is “remove the clutter” so that your “data can tell the story.” Would it be going to far if I suggested that… Read more ›